
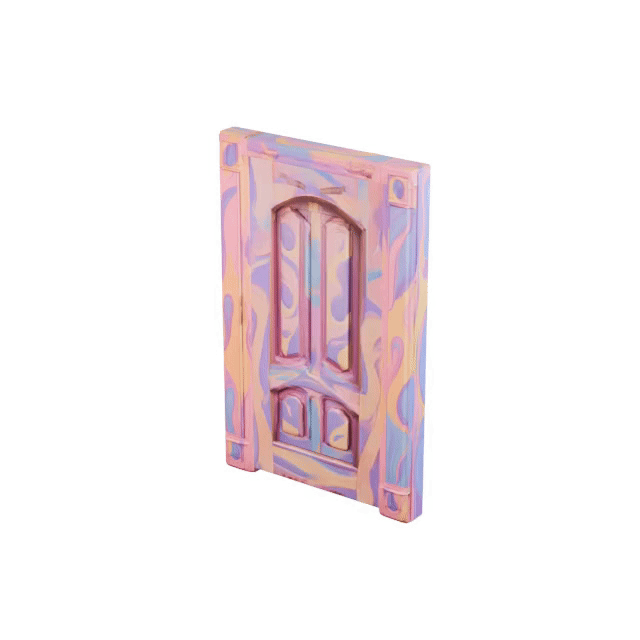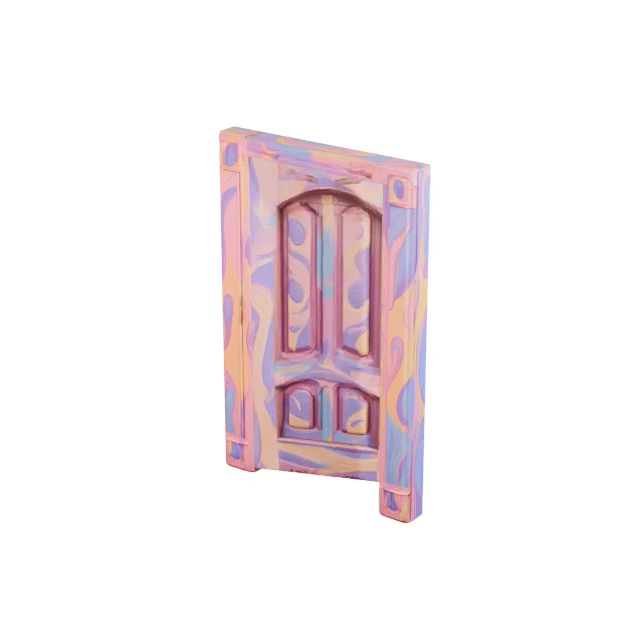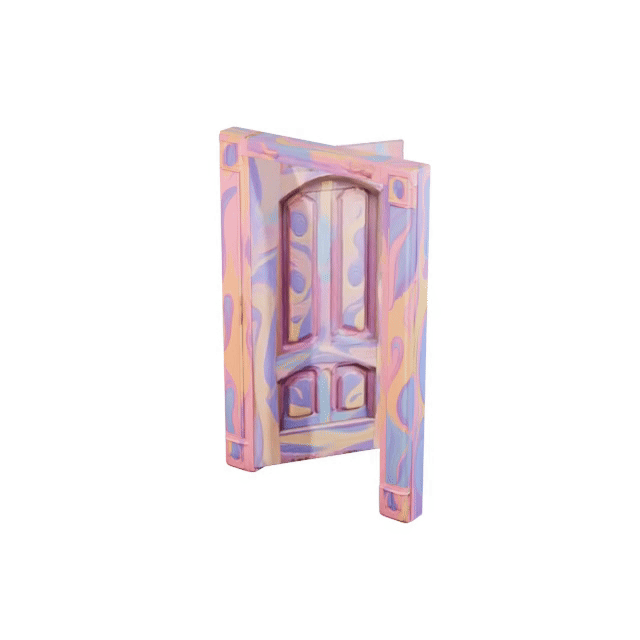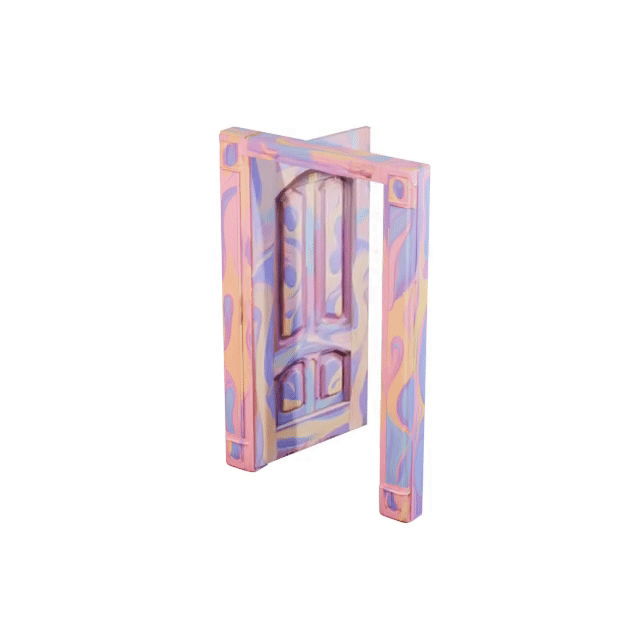






Articulated 3D objects are critical for embodied AI, robotics, and interactive scene understanding, yet creating simulation-ready assets remains labor-intensive and requires expert modeling of part hierarchies and motion structures. We introduce SPARK, a framework for reconstructing physically consistent, kinematic part-level articulated objects from a single RGB image. Given an input image, we first leverage VLMs to extract coarse URDF parameters and generate part-level reference images. We then integrate the part-image guidance and the inferred structure graph into a generative diffusion transformer to synthesize consistent part and complete shapes of articulated objects. To further refine the URDF parameters, we incorporate differentiable forward kinematics and differentiable rendering to optimize joint types, axes, and origins under VLM-generated open-state supervision. Extensive experiments show that SPARK produces high-quality, simulation-ready articulated assets across diverse categories, enabling downstream applications such as robotic manipulation and interaction modeling.
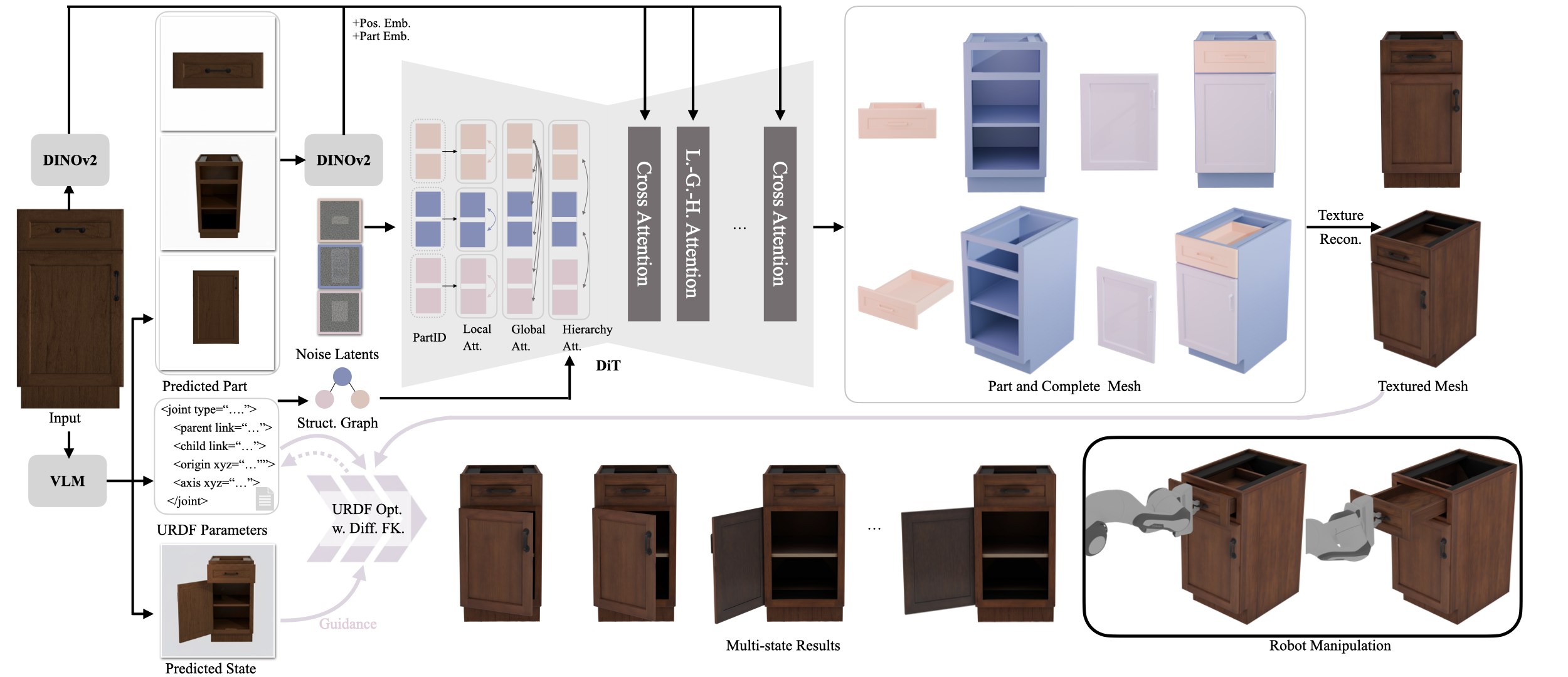
We use a VLM to generate per-part reference images, predicted open-state images, and URDF templates with preliminary joint and link estimations. A Diffusion Transformer (DiT) equipped with local, global, and hierarchical attention mechanisms simultaneously synthesizes part-level and complete articulated meshes from a single image with VLM priors. We further employ a generative texture model to generate realistic textures and refine the URDF parameters using differentiable forward kinematics and differentiable rendering under the guidance of the predicted open-state images.
We compare our results with OmniPart, PartCrafter, and URDFormer. Our method fulfills accurate, high-fidelity articulated object shape reconstruction.






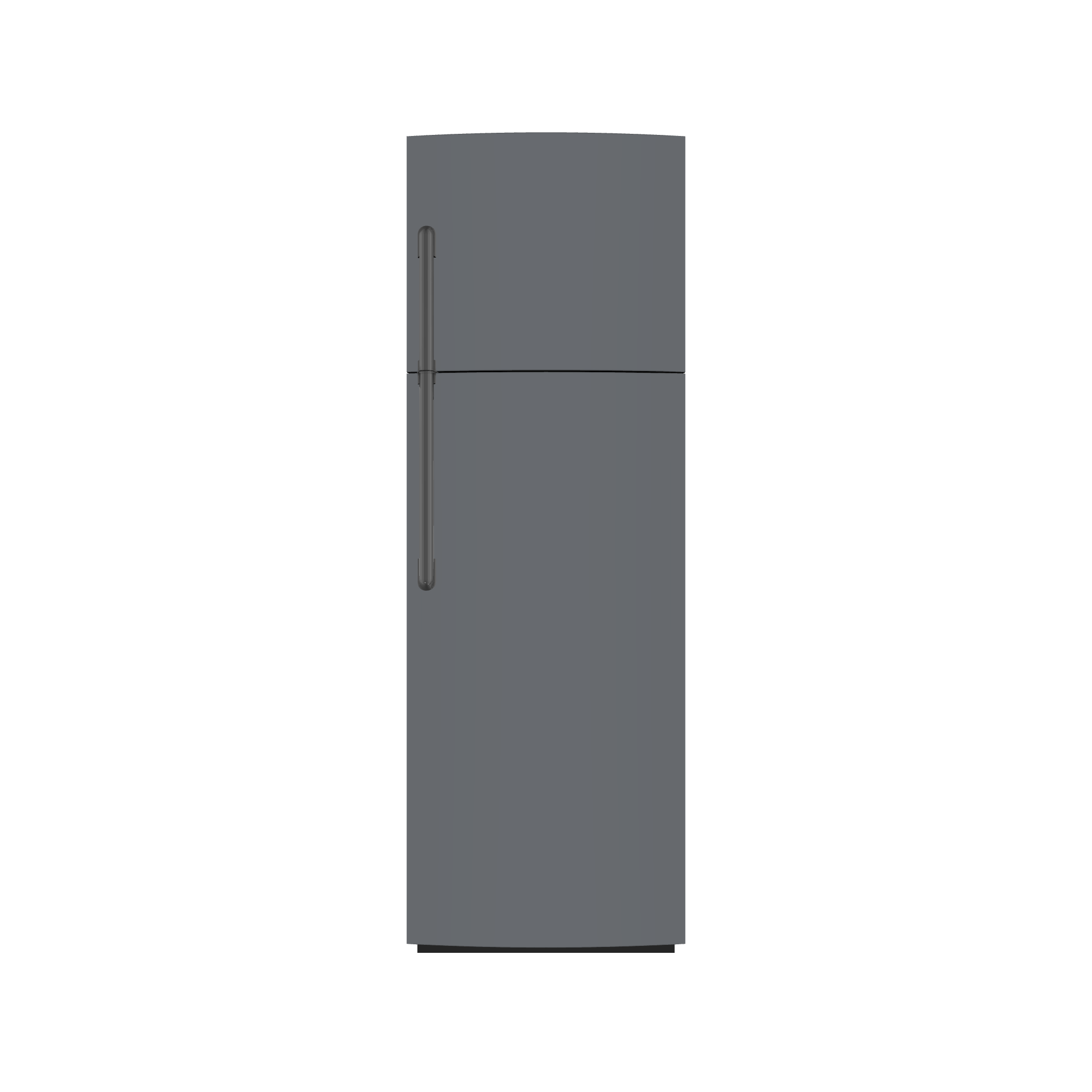


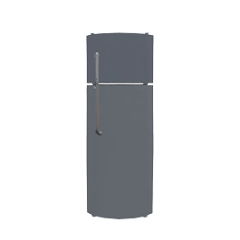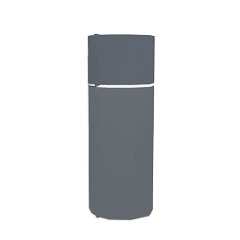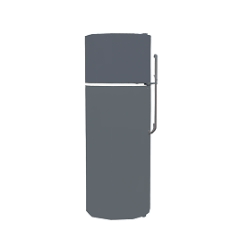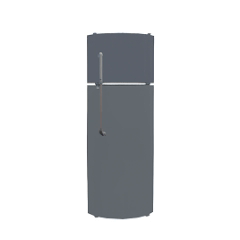















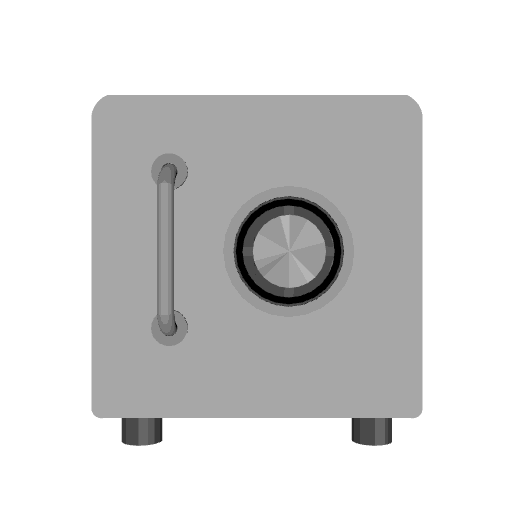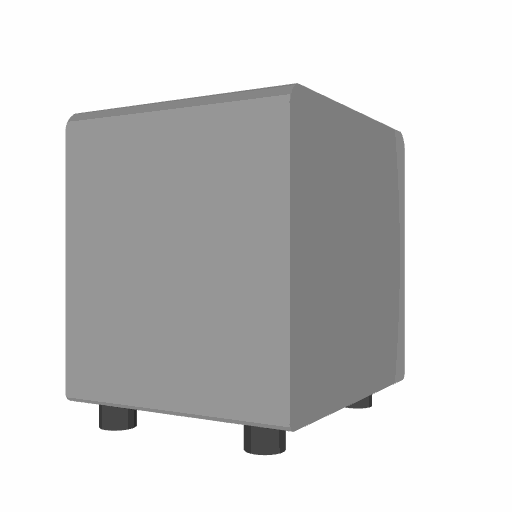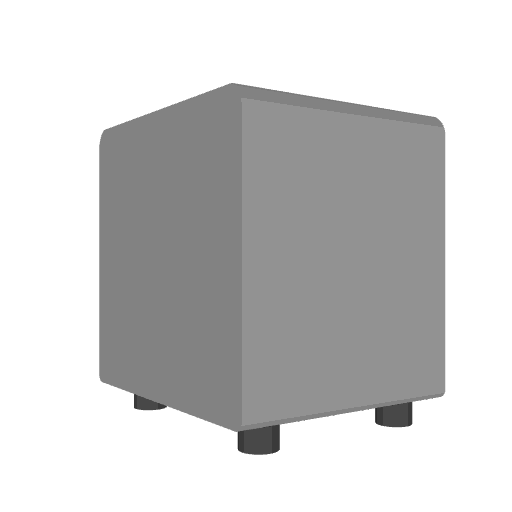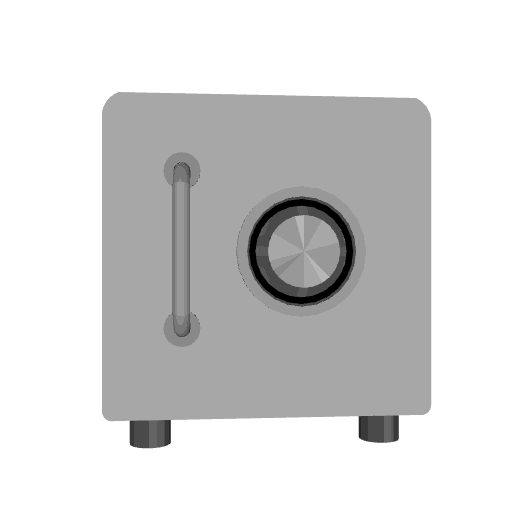










We compare our results with Articulate-Anything, Articulate-AnyMesh. The closed-state results are reconstructed or retrieved meshes, while the open-state configurations are obtained through kinematic transformations using the estimated URDF parameters. Our method achieves more accurate and physically consistent URDF estimation, leading to realistic articulation behavior.




















We thank all the members of the UCLA AIVC Lab for helpful discussions and feedback. We also thank Rosalinda Chen for her support in setting up the robotic manipulation tasks used to evaluate our generated assets in downstream applications. Finally, we thank Yuchen Lin for guidance on using PartCrafter and for help with adopting their implementation as the foundation of our codebase.
If you find our work helpful, please consider citing:
@misc{he2025spark,
title={SPARK: Sim-ready Part-level Articulated Reconstruction with VLM Knowledge},
author={Yumeng He and Ying Jiang and Jiayin Lu and Yin Yang and Chenfanfu Jiang},
year={2025},
eprint={2512.01629},
url={https://arxiv.org/abs/2512.01629}
}