








Monocular depth estimation remains challenging for transparent objects, where refraction and transmission are difficult to model and break the appearance assumptions used by depth networks. As a result, state-of-the-art estimators often produce unstable or incorrect depth predictions for transparent materials. We propose SeeClear, a novel framework that converts transparent objects into generative opaque images, enabling stable monocular depth estimation for transparent objects. Given an input image, we first localize transparent regions and transform their refractive appearance into geometrically consistent opaque shapes using a diffusion-based generative opacification module. The processed image is then fed into an off-the-shelf monocular depth estimator without retraining or architectural changes. To train the opacification model, we construct SeeClear-396k, a synthetic dataset containing 396k paired transparent-opaque renderings. Experiments on both synthetic and real-world datasets show that SeeClear significantly improves depth estimation for transparent objects.
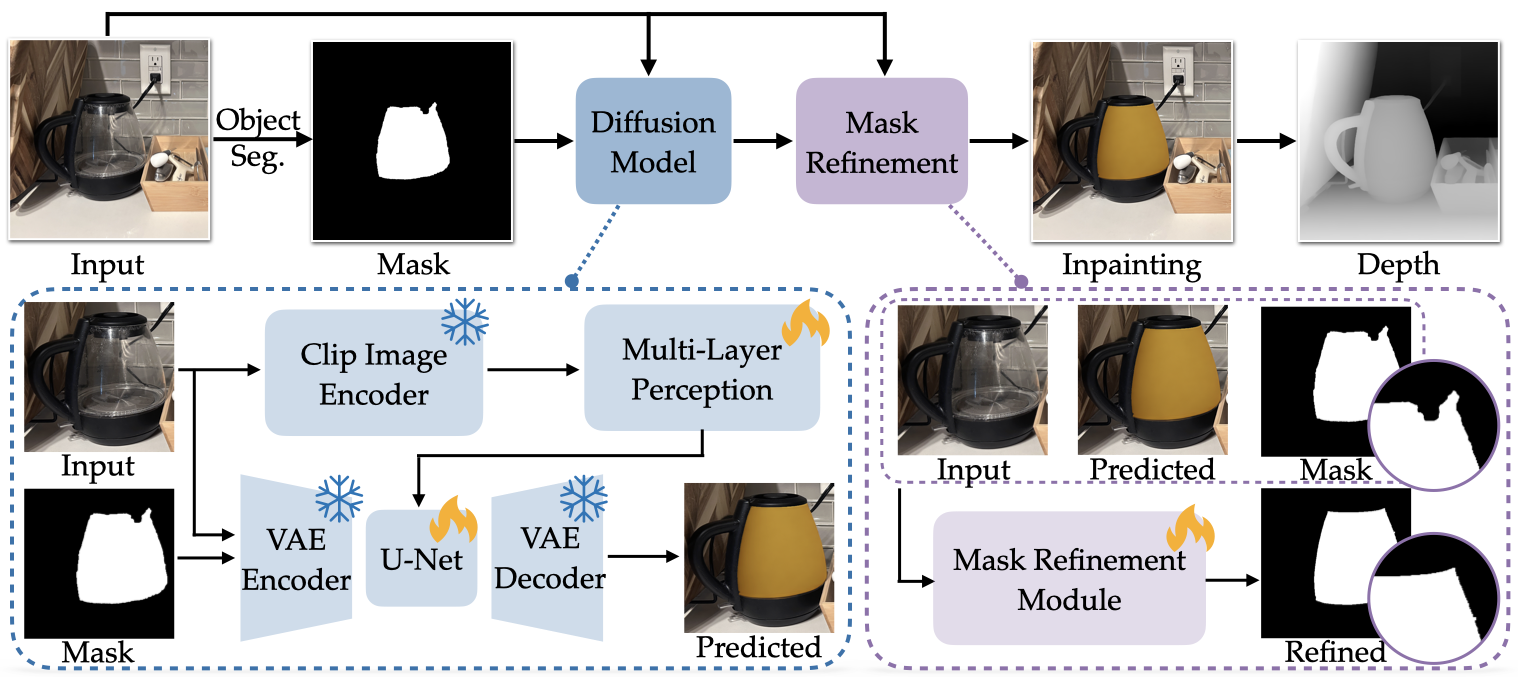
Starting from an image, we first apply a segmentation model to obtain the transparent object mask. Guided by the mask and the image, a latent diffusion model generates an opacified image of the transparent object. A mask refinement module then predicts a soft blending mask to alpha-composite the generated opaque region with the original background, producing the final composited image. The composited image is finally fed into a depth model to estimate accurate depth.
MoGe-2 exhibits depth leakage through transparent objects (e.g., a water bottle), while our method produces more accurate and consistent depth predictions.
We evaluate transparent-object depth estimation on ClearGrasp and TransPhy3D datasets. Compared with the baseline. SeeClear produces accurate transparent-object depth.
 Input
Input
 Ground Truth
Ground Truth
 Depth4ToM
Depth4ToM
 MODEST
MODEST
 D4RD
D4RD
 DKT
DKT
 Marigold
Marigold
 GenPercept
GenPercept
 GeoWizard
GeoWizard
 DA3
DA3
 MoGe-2
MoGe-2
 Ours
Ours
 Input
Input
 Ground Truth
Ground Truth
 Depth4ToM
Depth4ToM
 MODEST
MODEST
 D4RD
D4RD
 DKT
DKT
 Marigold
Marigold
 GenPercept
GenPercept
 GeoWizard
GeoWizard
 DA3
DA3
 MoGe-2
MoGe-2
 Ours
Ours
 Input
Input
 Ground Truth
Ground Truth
 Depth4ToM
Depth4ToM
 MODEST
MODEST
 D4RD
D4RD
 DKT
DKT
 Marigold
Marigold
 GenPercept
GenPercept
 GeoWizard
GeoWizard
 DA3
DA3
 MoGe-2
MoGe-2
 Ours
Ours
Comparison on TDoF20 dataset. Rows show Input, Ground Truth, DKT, and Ours. Each column is a different scene.



















